

昨晚,我差点把键盘砸了。
要测试几个新模型,几个几十G的权重文件在排队。浏览器自带下载器吭哧吭哧爬到99%,网络突然抽风闪断——
进度条归零,文件直接蒸发,连个断点续传的机会都没有。
我深吸一口气,打开GitHub,找到了Surge。

老实说,第一眼就觉得,这玩意有点不一样。
它是一个跑在终端里的下载管理器,有一个非常好看的 TUI 界面。
但不一样的地方在于,它做了一件事:
把一个文件,拆开,同时开多条连接一起下。
简单说就是,浏览器下载是一辆独轮车,一趟一趟往回运。
Surge 是直接调来一支车队,把文件切成块,分头跑。
最多可以开到 32 条并行连接。
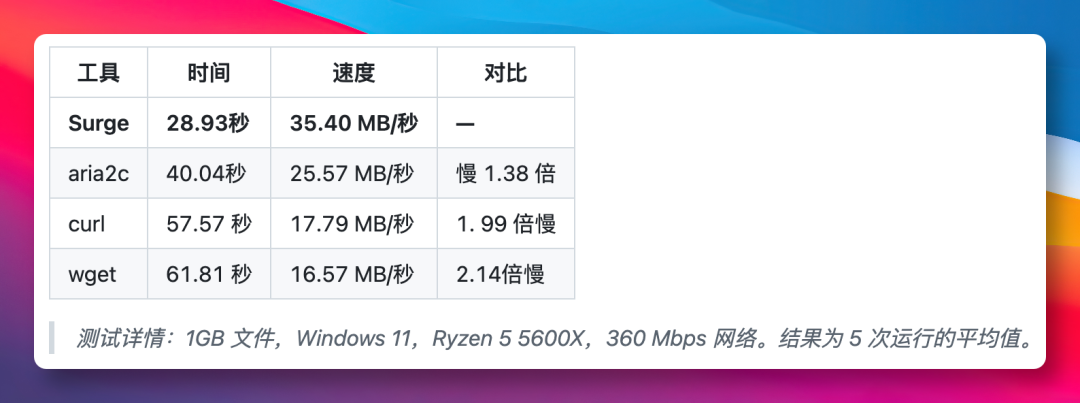
我看了一眼它的 Benchmark,对比数据放在那里。
同样下一个 1GB 的文件:wget,61 秒。curl,57 秒。aria2c,40 秒。Surge,28 秒。
我当时看了两遍,确认自己没看错。
这还不是最爽的。
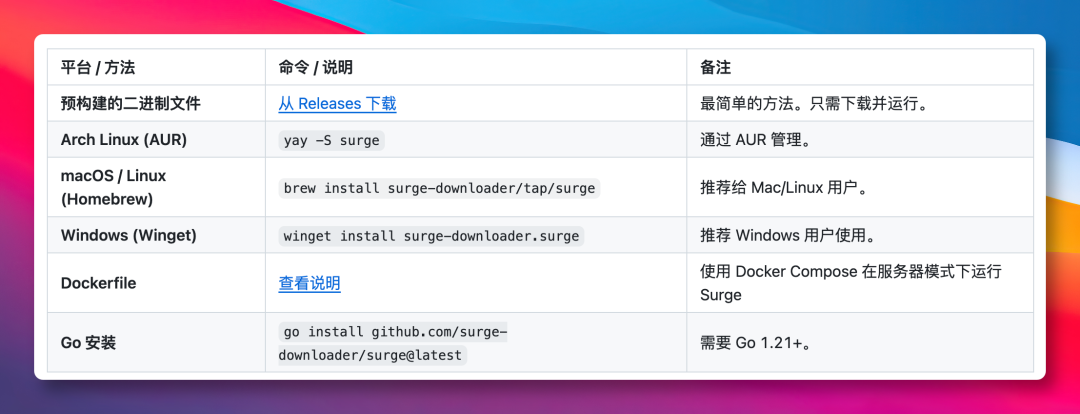
安装这个事,说实话,让我有点意外,因为真的比我想象的简单多了。
Mac 的话,一行命令:
brew install surge-downloader/tap/surge
Windows 的话:
winget install surge-downloader.surge
敲完,装好,直接在终端里输入 surge,就进了那个好看的 TUI 界面。
没有配置文件,没有注册账号,没有弹窗问你要不要订阅邮件。
就这样,进去了。
Surge 还有一个功能,我觉得对我这种经常同时拉好几个模型权重的人来说,特别实用。
它有一个 Server 模式,可以作为一个后台守护进程跑着。
surge server
开起来之后,你在任何一个终端标签里新加下载任务,全都会统一进这一个队列。
开了 10 个标签,也都是同一个下载引擎在调度。
不会出现一堆进程抢带宽互相干扰的情况。
甚至,如果你有个树莓派或者 NAS 放在家里跑着,也可以在上面跑 Surge 的 server mode,然后远程连上去,在本地的 TUI 里统一管理。
本地操作,远端下载,下好了文件已经在 NAS 上了。
有一说一,这个架构设计,对那种经常需要批量拉大模型的人来说,差点没让我觉得有点过分了。
它还有一个浏览器插件,装好之后,你在浏览器里点下载的时候,文件会直接被拦截,扔给 Surge 来处理,而不是走浏览器自己的那个单线程下载器。
Firefox 版本已经在 Mozilla 官方插件商店里了。
Chrome / Edge 的版本目前还在等官方上架,需要手动加载开发者模式来用。
我看了一眼,他们在 README 里写着正在筹钱交 Chrome Web Store 的费用,两个 CS 在读的大学生在课间攒的项目。
两个在考期中间抽时间写代码的学生,把这个工具放出来,免费给所有人用。
他们的 README 里最后写着,如果 Surge 帮你省了时间,可以给他们买杯咖啡。
不是什么宏大的愿景,不是什么改变世界的宣言。
就是,如果有用,就留着用。
我觉得开源精神里最动人的部分,其实不是什么大哲学,就是这个。
有人把自己觉得好用的东西,放在那里,然后说:
你们拿去用吧。
而很多年后,可能有另一个深夜正要叹气的人,在 GitHub 上乱翻的时候,找到了它。
然后,就不叹气了。
就像我昨晚一样。
项目地址
GitHub 项目地址:https://github.com/surge-downloader/Surge


回复