

2026年的AI进化速度,已经超出了大多数人的认知边界。
作为每天与AI共处十几个小时的从业者,我越来越感受到技术迭代的压迫感——昨天刚掌握的工具,今天可能就已经过时。这种加速度正在重塑整个行业的游戏规则。
就在昨夜,智谱科技扔下了一枚重磅炸弹:GLM-5正式开源,这是其迄今为止最强的基座模型。
在Artificial Analysis全球评测榜上,GLM-5力压Gemini,跻身全球第四,开源阵营排名第一。
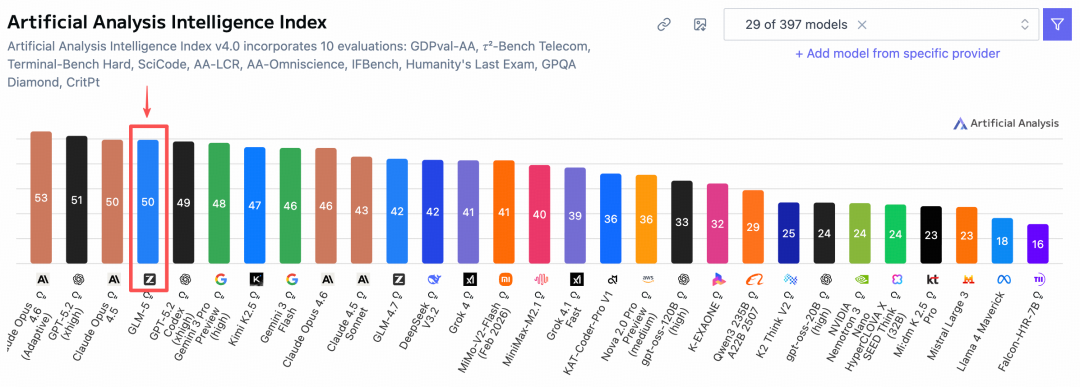
这个结果并不意外。早在GLM-4.7发布时,我就预判过下一代旗舰会在春节前后亮相,没想到智谱直接跳过了4.8/4.9,版本号从4.x跃迁至5.0——这绝非简单的数字游戏,而是底层架构的质变。
GLM-5的核心升级逻辑:从"写代码"到"建系统"
当行业还在沉迷于Vibe Coding(一句话生成炫酷页面)的军备竞赛时,GLM-5选择了一条更难的路:Agentic Engineering(智能体工程)。
它不再满足于生成漂亮的前端特效,而是进化为能够处理复杂长链路任务的系统架构师——脏活、累活、需要多步骤协调的工程化工作,才是它的主战场。
硬件规格方面,参数规模从355B膨胀至744B(激活40B),预训练数据量从23T扩容至28.5T。
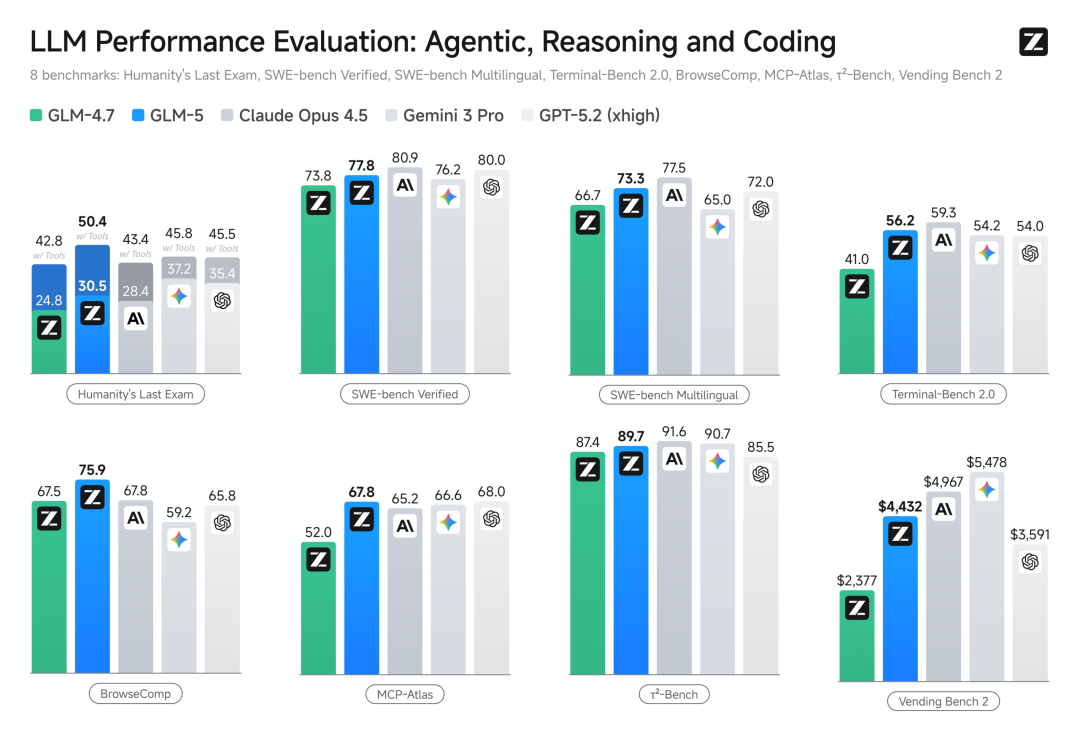
在SWE-bench-Verified编程基准测试中,GLM-5拿下77.8分,超越Gemini 3 Pro,与Claude Opus 4.5处于同一水平线。
免费体验地址: z.ai
开源仓库:
- GitHub:https://github.com/zai-org/GLM-5
- Hugging Face:https://huggingface.co/zai-org/GLM-5
- ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-5
关于"Pony"的谜题
过去一周,X平台上突然冒出一个代号Pony的神秘模型,引发大量猜测。
谜底揭晓:Pony就是GLM-5的测试代号(马年将至,命名颇具东方意味)。
我通过OpenRouter将其接入Claude Code进行实测,结论只有两个字:强悍。这款模型在开发者社区的热度持续飙升。

实战案例1:7分钟生成API中转站
仅用7分钟,Pony/GLM-5一次性搭建了一个完整的API中转服务——包含后端逻辑、数据库设计和动态数据管理。虽然只是个MVP,但功能完备,真正做到了"麻雀虽小,五脏俱全"。
深度体验:Plan Mode下的架构师思维
经过长时间测试,我发现GLM-5在任务规划阶段展现出与Claude Opus极为相似的特质:极度严谨的结构化思维。
熟悉Opus的用户都知道,它在执行前会输出一份详尽且逻辑严密的实施路线图。GLM-5现在具备了同样的能力。
实战案例2:多AI聚合浏览器插件
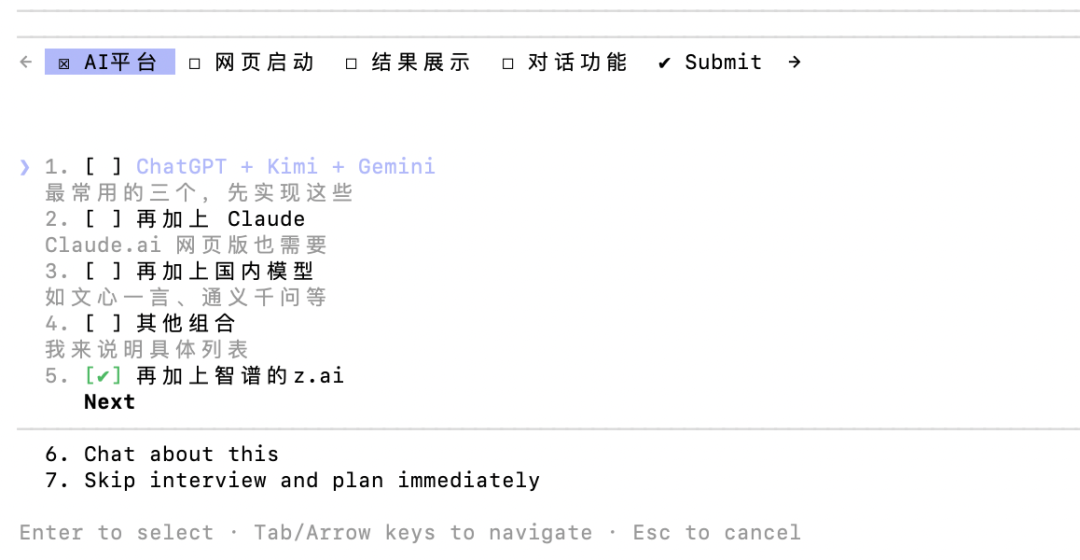
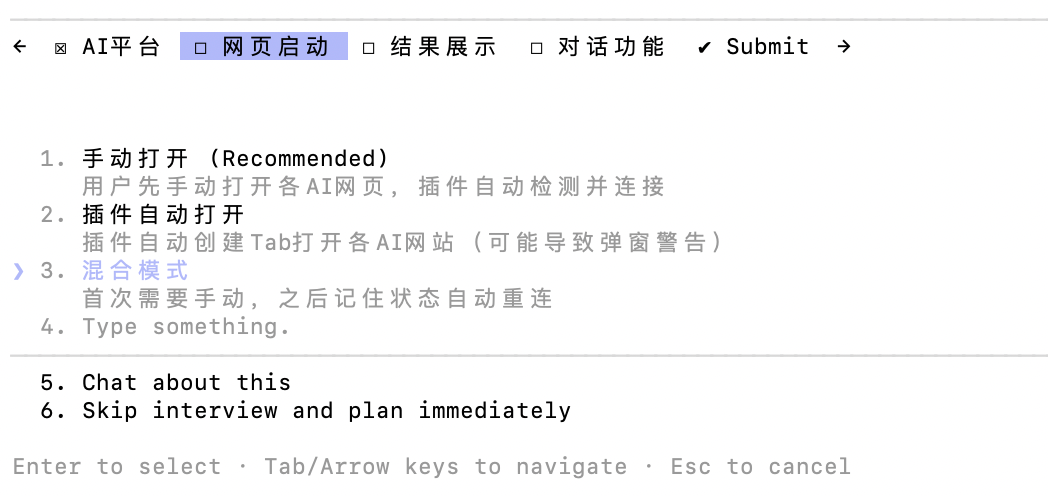
我长期面临一个痛点:手头持有Gemini、ChatGPT、Kimi、智谱等多个AI会员,查询资料时需要反复切换窗口、复制粘贴、对比答案——效率极低。
我需要一个浏览器插件,能够在一个界面内同时向四个AI发送相同问题,并统一展示回复。
但这涉及复杂的DOM解析和反爬机制破解,每个平台的页面结构各异,防护策略不同。
我将这个复杂需求提交给GLM-5,开启Claude Code的Plan Mode:
注:上述输出的条理性和细致度,与Claude Opus的风格高度吻合
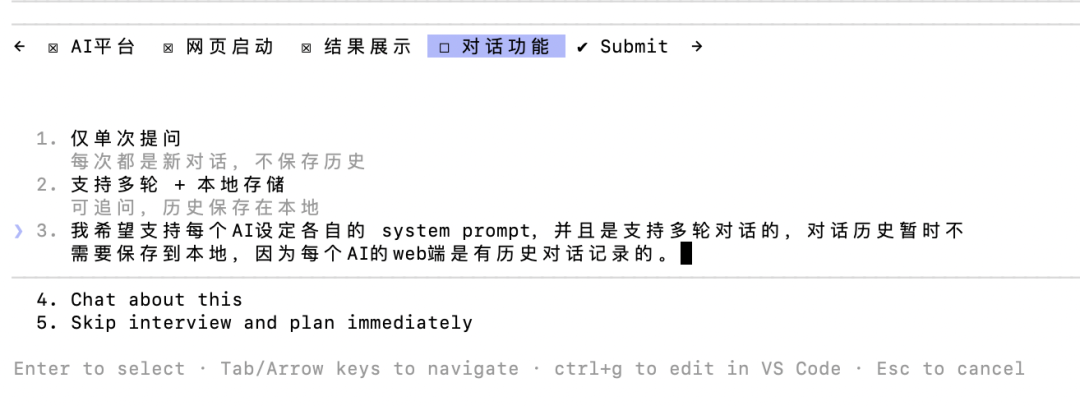
模型还会主动进行需求澄清:

最终生成的方案长达633行,覆盖从架构设计到异常处理的完整链路:
执行阶段,仅项目初始化就耗时50分钟。期间GLM-5自动调用Playwright MCP工具,自主打开浏览器,分析目标网站的DOM结构,定位输入框与发送按钮的Class名,捕获文本流返回机制——全程无需人工干预,我一行代码未写。
(遗憾未录屏,当时正在并行处理其他任务)
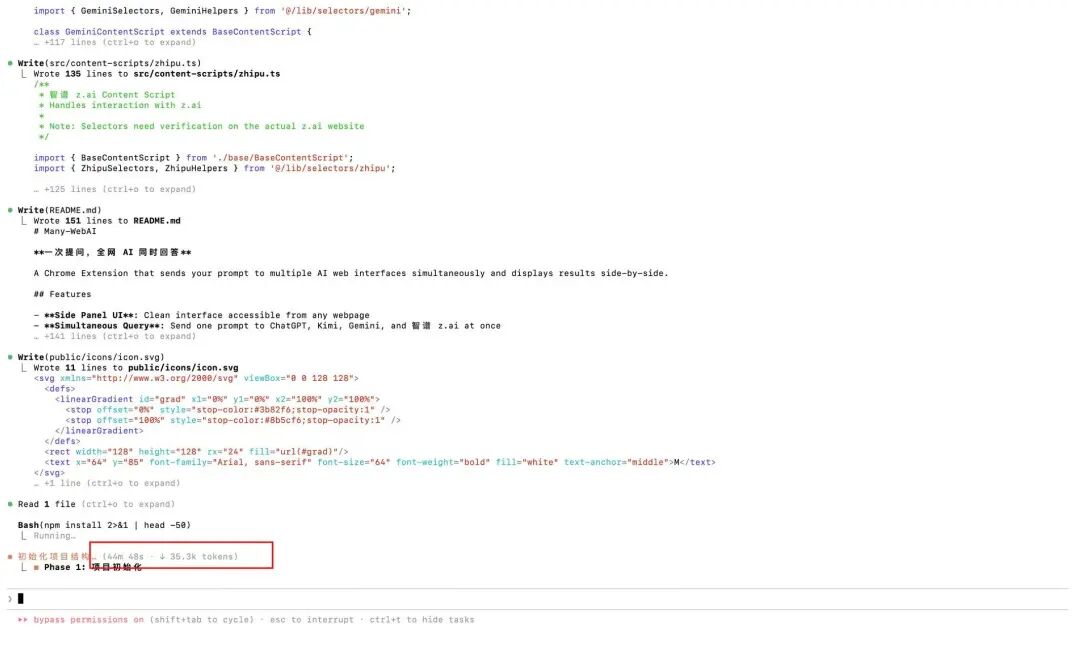
成果交付:一次提问,全网AI同步响应的聚合插件,完全匹配原始需求。
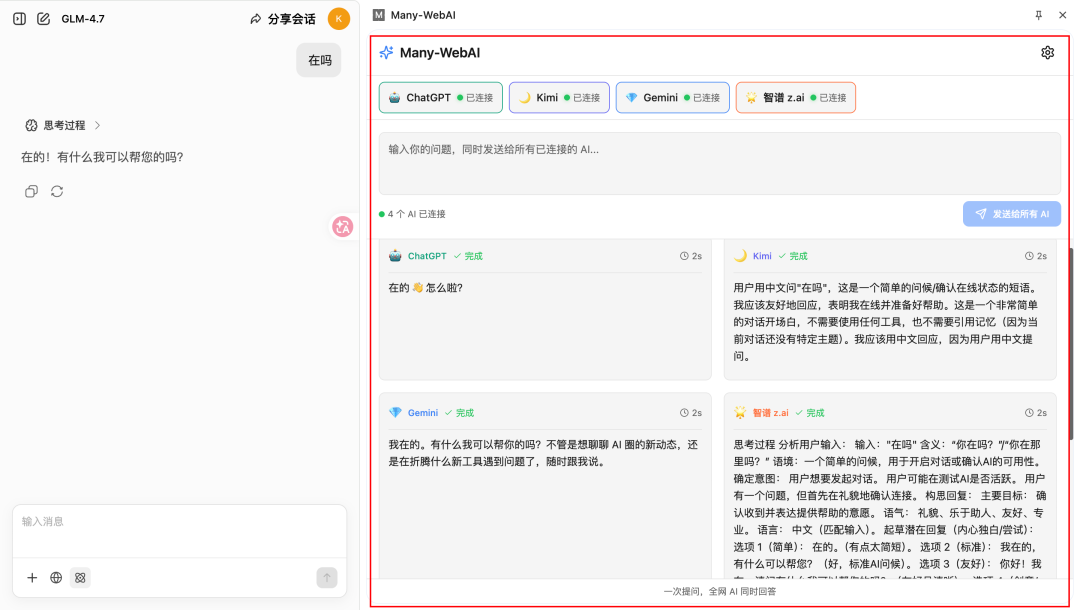
实战案例3:数字人营销平台重构
此前我搭建了一个数字人营销视频生成平台。为提升体验,我重构了前端,却导致前后端接口错位、历史逻辑失效、Bug丛生,项目陷入混乱。
我将主流程的Debug任务全权交给GLM-5:
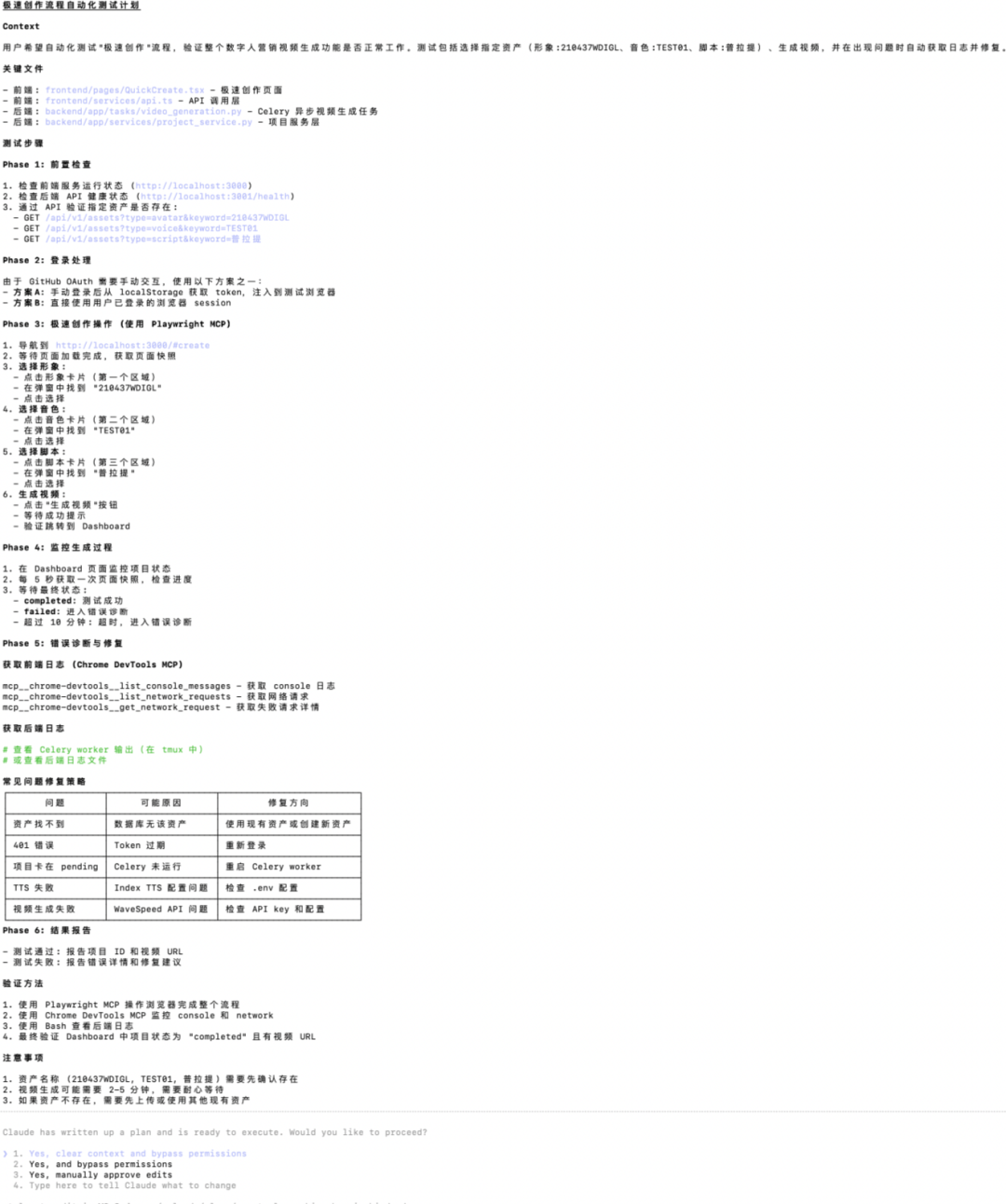
确认方案后进入执行(全程调用浏览器MCP进行调试)。
执行速度并不快,但这并非模型算力不足——Token生成速度可达每秒上千。耗时主要源于任务本身的复杂性:持续自我反思、工具调用、测试验证,以及依赖安装和命令执行。
整个修复流程耗时40分钟。
质疑者会说:40分钟?我自己都写完了。
但关键在于:这40分钟里,我在刷视频、遛狗,而GLM-5在专注处理最令人头秃的Bug定位和重构工作。
交付结果:主要问题全部解决。
后续测试中发现的小瑕疵,通过补充指令让其修复优化。但在Bug修复和功能调优方面,GLM-5展现出极高的可靠性。
传统AI修Bug的噩梦是越修越乱、拆东补西。过去需要严格的工程化约束:限定修改范围、写入规则文件、单Bug单修、回归测试...流程繁琐。
GLM-5的体验完全不同:只需描述现状、抛出错误日志、明确预期行为,几乎都能一次修复成功,且无副作用。
我甚至尝试在同一轮对话中一次性抛出四个独立Bug,它依然能够条理清晰地逐个击破:
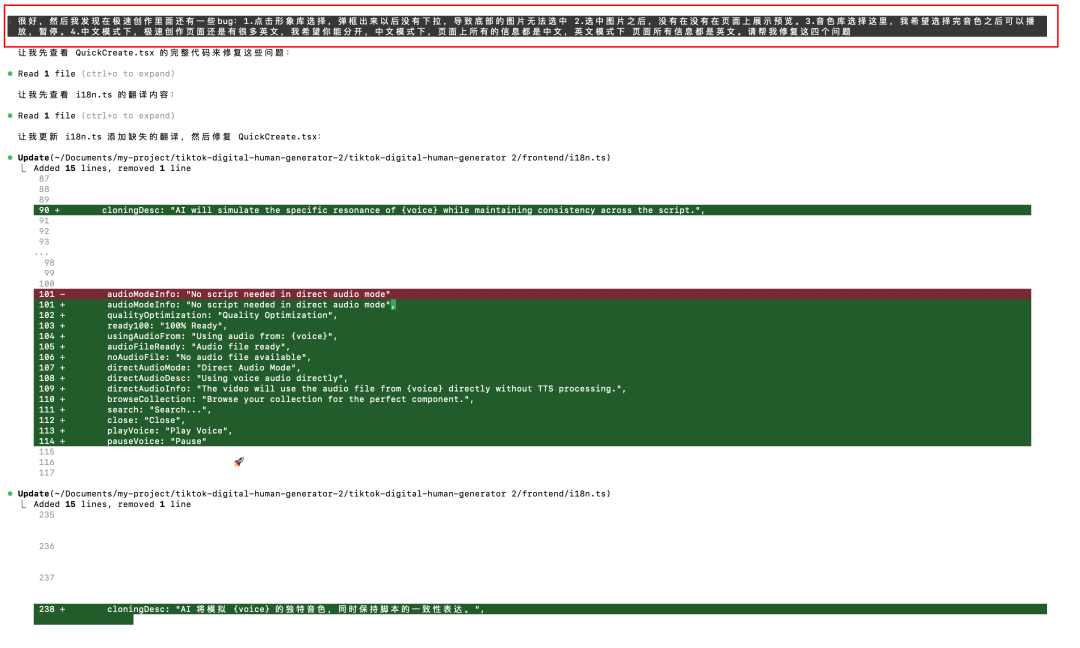
这种工程稳健性带来的安全感,彻底改变了人机协作的模式。
现在我可以将任何复杂开发任务放心交给GLM-5,出错概率极低。即便偶发异常,Claude Code的回滚机制也能瞬间还原。
整个项目经GLM-5全面优化后,核心流程已全部跑通。我计划近期将其开源(需将模型API部分抽离为配置项)。
结语:国产AI的硬核崛起
体验完GLM-5,最深刻的感受是:中国AI的硬实力正在改写全球格局。
就在几天前,字节跳动的Seedance 2.0在视频生成领域登顶,超越Sora2和Veo3.1。
如今,智谱GLM-5在AI Coding这条硬核赛道上,同样交出了超预期的答卷。
我们曾反复强调国产模型在逻辑推理、代码生成上与GPT、Claude、Gemini存在代差。
今天,GLM-5用实际表现宣告:这个代差正在消失。
它不是Demo玩具,而是能够承担系统构建、长任务处理、复杂问题解决的生产级工具。
更重要的是,它完全开源。
这意味着每个开发者、每家企业,都能以更低成本获得顶级AI架构师的能力。
目前GLM-5的Coding服务已出现算力紧张,官方公告正在紧急扩容——接入的是基于国产芯片的万卡集群。

算力投入加大导致价格上调,还好我提前锁定了Max套餐。
从底层芯片到上层模型,从算力基建到应用生态,一条完全自主可控、世界顶级的AI技术栈正在成型。
这不仅是技术的胜利,更是产业话语权的重新分配。


回复